Web Scrapping with Python:


Background
Web Scrapping simply means extracting data from online websites, documents, and files that can use for personal purposes or ML datasets, Marketing, etc.
Many automated tools are available for this but if you wanted to learn how python can do this get ready.
So we will use Python’s easiest web-scraping library, Beautiful Soup.
What Do You Need To Scrape the Web?
Requests library: The requests library is the standard Python Lib. With it, we can make HTTP requests to get data from a targeted website which we will scrape.
Beautiful Soup: Beautiful Soup helps us parse HTML and XML documents. It creates a parse tree for parsed pages that can be used to extract data from targeted websites. You don’t need the previous Beautiful Soup.
Before we start, make sure you have Python 3.x installed on your computer. If so, let’s start with the tutorial by setting up Beautiful Soup in Python!
Requests get data from a web server and Beautiful Soup is a bowl that stores all data in a segregated format for easier actions of data extraction.
Setting up all the library's
Install the Requests library: Run the following command in your command prompt or terminal:
pip install requestsInstall Beautiful Soup: Run the following command in your command prompt or terminal:
pip install bs4Install a parser: We need a parser to extract data from HTML documents. In this guide, we’ll use the
lxmlparser. To install this parser, run the following command:pip install lxml
Section 1: Scraping a Single Page
I’ll guide you through each line of the code we need to write to build our first scraper. You can find the full code at the end of this article. Let’s get started!
Importing libraries
The following are the libraries required to scrape with Beautiful Soup:
from bs4 import BeautifulSoup import requestsGet the HTML of the website
We’re going to scrape a website that contains thousands of pages of movie lists with their transcripts. We’ll start by scraping one page and then we'll see how to scrape multiple pages.
First, we define the link. In this case, I’m choosing the transcript of the movie Inception, but you can choose any movie you want.
Requesting the content from the website using Requests.
requests.getis for receiving the response code we save in theresultvariable. We do not required the response code but we require the content i.e. the text inside it. Thus we used the.textmethod to obtain the content of the website. Finally, we use thelxmlparser to obtain thesoup, which is the object that contains all the data in the nested structure that we’re going to reuse later.website = 'https://subslikescript.com/movie/Titanic-120338' result = requests.get(website) content = result.text soup = BeautifulSoup(content,'lxml') # BeautifulSoup is for to process pull data from html # soup is object storing the parserd html content. print(soup.prettify())Once we have the
soupobject, the HTML in a readable format can be easily obtained by using.prettify(). Although we can use the HTML printed in a text editor to locate elements, it’s much better to go straight to the HTML code of the specific element we want. We’ll do this in the next step.
Analyzing the website and HTML code
An important step before we move on to writing code is analyzing the website we want to scrape and the HTML code obtained in order to find the best approach to scrape the website. Below, you can find a screenshot of one transcript. The elements to scrape are the movie title and the transcript.
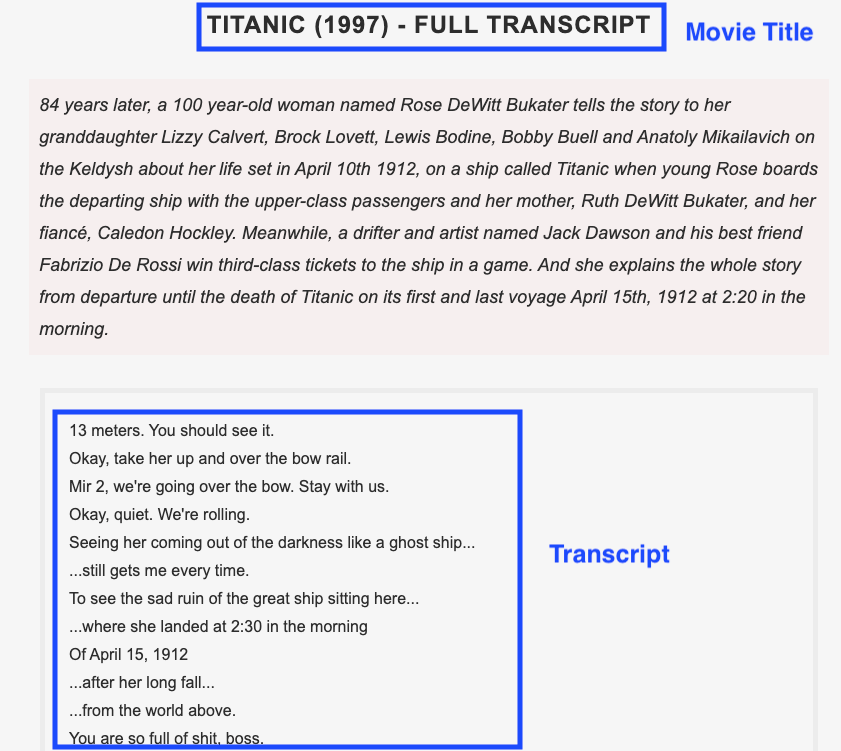
To obtain the HTML code of a specific element, follow these steps:
Go to the website of the transcript you want.
Hover on either the movie title or transcript and then right-click. A list will be displayed. Choose “Inspect” to open up the source code of the page.
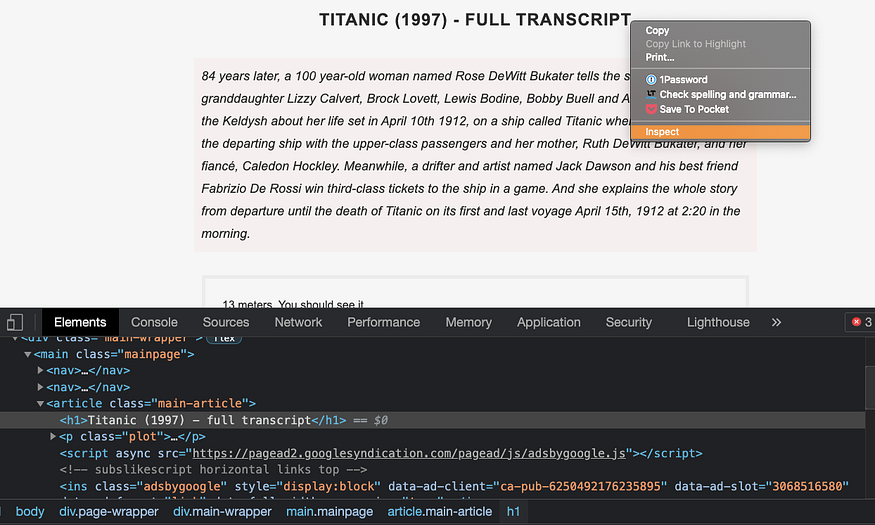
Below, you can find a smaller version of the HTML code obtained after clicking inspect. We’re going to use this HTML code as a reference for locating elements in the next step.
Locating an element with Beautiful Soup
Locating an element in Beautiful Soup is simple. You just have to apply the .find() method to the soup created before.
As an example, let’s locate the box that contains the movie title, description, and transcript. It’s inside an article tag and has a class named “main-article”. We locate that box with the following code:
title = soup.find('article',class_="main-article")
Now let’s locate the movie title and transcript. The movie's name is inside an h1 tag and doesn’t have a class name. After we locate it, we use the .text method to obtain the text inside the node:
name = title.h1.text.split()[:-3]
#name = title.h1.text.split()
#gives us all the content inside h1 text so use split and removed "- full transcript"
The transcript is inside a div tag and has a class named ”full-script”. To obtain the text in this case, we’re going to modify the default parameters inside the .get_text() method. First, we set strip=True to remove leading and trailing spaces. Then we add a blank space to the separator separator=’ ‘ so words have a blank space after every new line (\n).
transcript = box.find('div', class_='full-script')
transcript = transcript.get_text(strip=True, separator=' ')
So far, we have successfully scraped the data. Print the title and transcript variables to make sure everything is working fine until now.
Exporting data in a txt file
You can export the data scraped to reuse it later if you want. You can store data in CSV, JSON, and more formats. For this example, I’ll store the data extracted in a .txt file.
To do so, we need to use the with keyword as shown in the code below:
with open(f'{title}.txt', 'w') as file:
file.write(transcript)
Keep in mind that I’m using f-string to set the file name as the movie title. After running the code, a .txt file should be located in your working directory.
Now that we’ve successfully scraped data from one page, we’re ready to scrape transcripts from multiple pages!
Section 2: Scraping Multiple Pages and movies names
Below, you can find the screenshot of the first page of the website with movie transcripts. The website has 1,234 pages with around 30 movie transcripts per page.
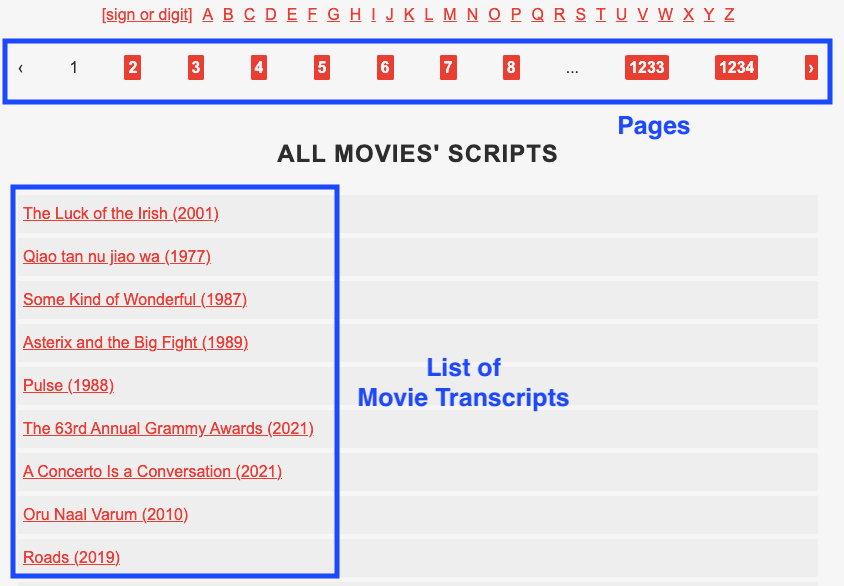
In this second part, I’m going to show you how to scrape multiple links by getting the href attribute of each link. First, we have to modify the website to scrape. The link to the website shown above is subslikescript.com/movies.
Our new website variable will be the following:
root = 'https://subslikescript.com'
website = f'{root}/movies'
I also defined a root variable that will help us scrape multiple pages later.
Getting the href attribute
Let’s get first the href attribute of the 30 movies listed on one page. To do so, inspect any movie title inside the “List of Movie Transcripts” box presented in the screenshot above.
After this, you should get the HTML code. An a tag should be highlighted in blue. Each a tag belongs to a movie title.
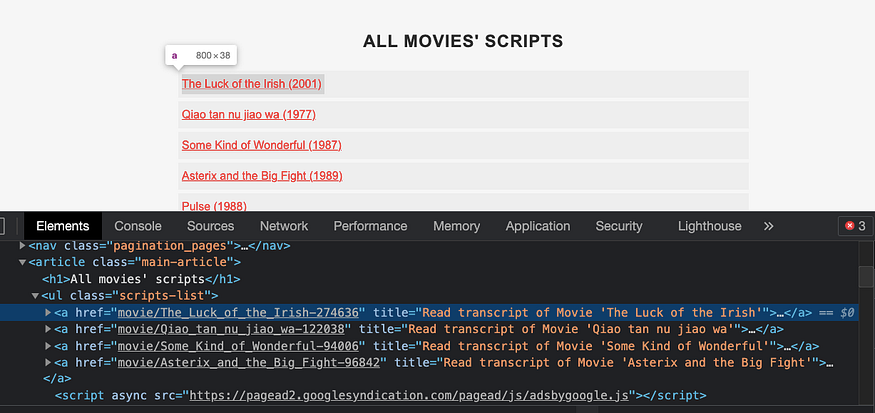
As you can see, the links inside the href don’t contain the root subslikescript.com.This is why I defined a root variable before to concatenate it later.
Let’s locate all the a elements on the page.
Locating multiple elements with Beautiful Soup
To locate multiple elements in Beautiful Soup, we have to use the .find_all() method. We need to add the parameter href=True to be able to extract the link that corresponds to each movie transcript.
box.find_all('a', href=True)
To extract the links from the href, we have to add ['href'] to the expression above. However, the .find_all() method will return a list, so we have to loop through it and get the hrefs one by one inside the loop.
for link in box.find_all('a', href=True):
link['href']
To store the links, we can use list comprehension, as shown below:
links = [link['href'] for link in box.find_all('a', href=True)]
print(links)
If you print the links list, you will see the links we want to scrape. We’ll scrape each page in the next step.
Looping through each link
To scrape the transcript of each link, we’ll follow the same steps we did before for one transcript. This time, we’ll include those steps inside the following for loop.
for link in links:
result = requests.get(f'{root}/{link}')
content = result.text
soup = BeautifulSoup(content, 'lxml')
As you might remember, the links we stored previously don’t contain the root subslikescript.com, so we have to concatenate it with the expression f’{root}/{link}’.
The rest of the code is the same as we wrote for the first part of this guide. The full code for this project is the following:
In case you want to navigate through the pages listed on the web, you have two options:
Option 1: Inspect any of the pages displayed on the website (e.g. 1,2,3, …1234). You should obtain an
atag that contains anhrefattribute with the links for each page. Once you have the links, concatenate them with the root and follow the steps shown in Section 2.Option 2: Go to page 2 and copy the link obtained. It should look like this: subslikescript.com/movies?page=2. As you can see, there’s a pattern the website follows for each page:
f’{website}?page={i}’. You can reuse the website variable and loop between the numbers1and10if you want to navigate the first ten pages.